Encoder-Decoder、Encoder-only和Decoder-only架构的区别
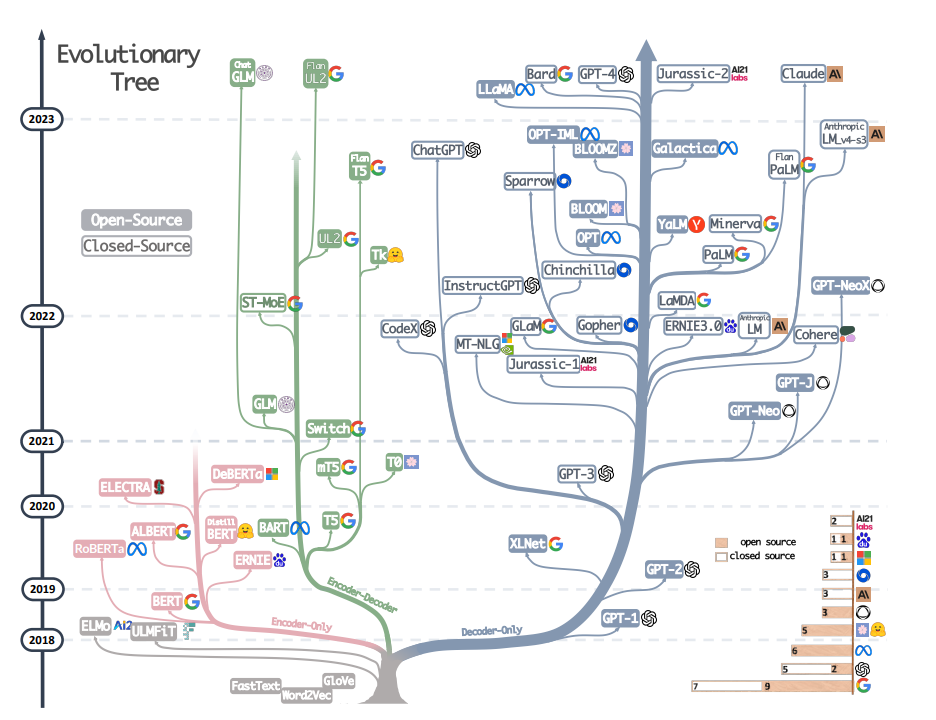
首先,语言模型最底层的行事逻辑就是对现实生活中的信息进行近似模拟,即发现数据内部的一般模式(以参数的形式进行存储),从而达到可以模仿训练数据的目的。比如可以把语言模型看成是一个小孩,我们输入一些翻译的例子,语言模型的终极目标就是模拟学习人类给出给的翻译例子的特征,从而面对新的句子也能基于习得经验进行翻译。大语言模型(Large Language Model,LLM)其实就是由最原始的语言模型(下图灰色部分)演化而来,重点在于”大”这个字,这个字背后的含义就是非常深层的神经网络,一开始可能只有6层,现在可以叠层发展到几百层几千层。研究者发现同样的架构下,神经网络层数越多,消耗的显存(GPU)和内存(CPU)资源就越多,模拟效果也会更好。这也是为什么目前大语言模型达到了瓶颈,不是技术瓶颈,而是硬件达到了瓶颈。当前LLM的发展大多都是基于transformer架构,具体参见下面的树图,非tranformer架构的模型都用灰色标识出来了。
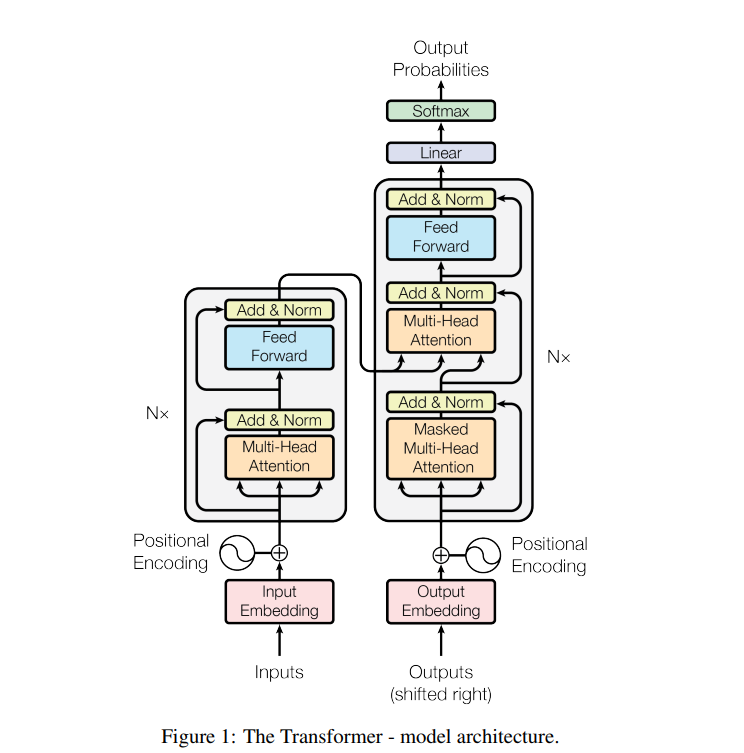
 Tranformer架构诞生于”Attention is all you need”这篇论文,因此这篇论文基本奠定了现在大语言模型的架构总基调。Transformer架构其实就是N × 6层Encoder-Decoder架构(下图Figure 1左侧部分就是Encoder,右侧是Decoder),其核心贡献是分散在Encoder-Decoder架构中的自注意力机制(Self-Attention),其中Decoder还多了一个掩码自注意力机制以区分于Encoder。而为什么这篇论文的作者没有获得诺贝尔奖,反而是提出back propagation(反向传播,梯度下降对神经网络进行模拟)的作者Geoffrey Hinton(杰弗里·辛顿)获得诺贝尔奖,是因为这个架构中离不开的关键部分是子注意力机制后面的Feed forward network(FFN)前馈神经网络,FFN网络里最关键的模拟算法就是反向传播。可以说没有反向传播,神经网络就没办法进行学习和近似模拟。
Tranformer架构诞生于”Attention is all you need”这篇论文,因此这篇论文基本奠定了现在大语言模型的架构总基调。Transformer架构其实就是N × 6层Encoder-Decoder架构(下图Figure 1左侧部分就是Encoder,右侧是Decoder),其核心贡献是分散在Encoder-Decoder架构中的自注意力机制(Self-Attention),其中Decoder还多了一个掩码自注意力机制以区分于Encoder。而为什么这篇论文的作者没有获得诺贝尔奖,反而是提出back propagation(反向传播,梯度下降对神经网络进行模拟)的作者Geoffrey Hinton(杰弗里·辛顿)获得诺贝尔奖,是因为这个架构中离不开的关键部分是子注意力机制后面的Feed forward network(FFN)前馈神经网络,FFN网络里最关键的模拟算法就是反向传播。可以说没有反向传播,神经网络就没办法进行学习和近似模拟。
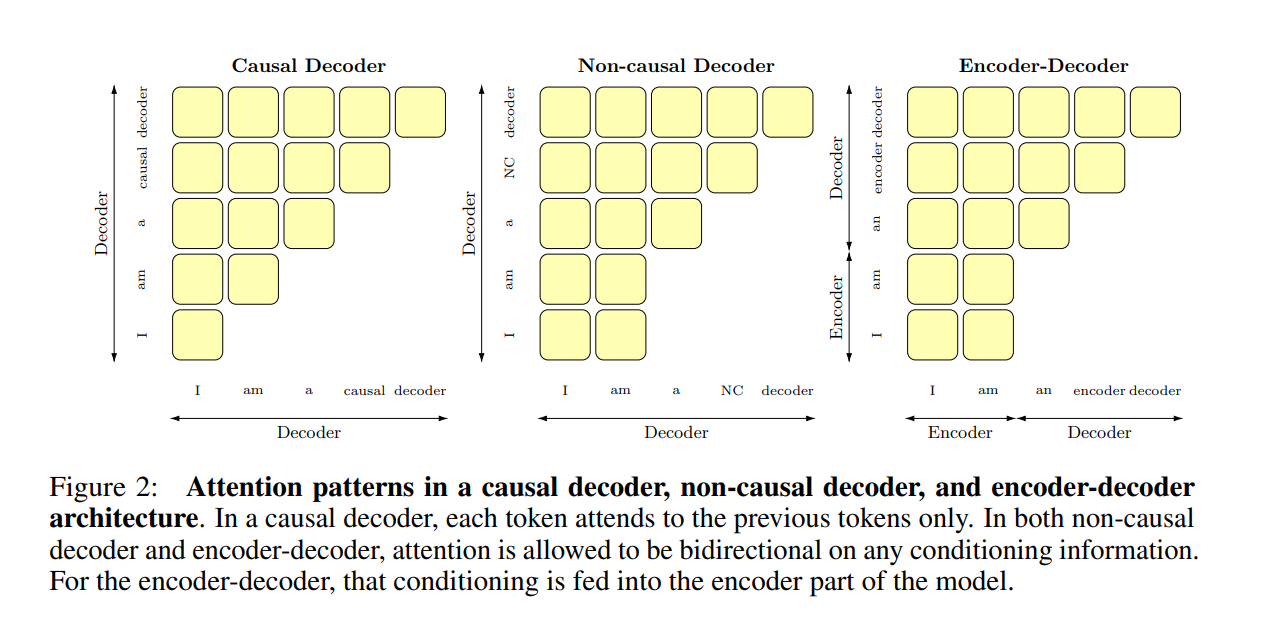
Encoder- decoder、Encoder-only、Decoder-only都是基于Transformer架构的模型架构,代表模型分别是T5、BERT、GPT,GLM模型采用的是encoder- decoder的框架,现在模型效果也还不错,还有以UNILM为代表的PrefixLM(相比于GPT只改了attention mask,前缀部分是双向,后面要生成的部分是单向的causal mask)。
-
这几个框架擅长的任务不同。网络的泛泛之谈教程总会说:
“Encoder-Decoder架构通常用于处理一些需要在输入和输出间建立精确映射的任务,比如机器翻译、文本摘要等。在这些任务中,理解输入的精确内容并据此生成特定的输出是非常重要的。而基于这种架构训练出来的模型,一般只能应用于某种特定的任务,比如一个专为机器翻译训练的Encoder-Decoder模型可能不适合直接用于文本摘要或其他类型的任务。
Decoder only架构则具有更强的灵活性。基于这种架构训练得到的模型可以处理多种不同类型的文本生成任务,如聊天机器人、内容创作、问答、翻译等等,不需要针对每一种任务进行专门的训练或调整,也不需要在输入和输出间构建严格的映射关系”
Encoder-only架构代表就是BERT了,因为它用masked language modeling预训练,不擅长做生成任务,做NLU一般也需要有监督的下游数据微调;相比之下,decoder-only的模型用next token prediction预训练,可以兼顾理解和生成,在各种下游任务上的zero-shot和few-shot泛化性能都很好。
值得一提的是,一部分双向attention的encoder-decoder和Prefix-LM(non-causal decoder)并没有被大部分大模型工作采用(它们也能兼顾理解和生成,泛化性能也不错),是因为:
-
用过去研究的经验说话,decoder-only的泛化性能更好:ICML 22的What language model architecture and pretraining objective works best for zero-shot generalization?. 在最大5B参数量、170B token数据量的规模下做了一些列实验,发现用next token prediction预训练的decoder-only模型在各种下游任务上zero-shot泛化性能最好;另外,[许多工作]([2] Dai, Damai, et al. “Why can gpt learn in-context? language models secretly perform gradient descent as meta optimizers.”arXiv preprint arXiv:2212.10559(2022).)表明decoder-only模型的few-shot(也就是上下文学习,in-context learning)泛化能力更强。
-
注意力满秩的问题,双向attention的注意力矩阵容易退化为低秩状态,而causal attention的注意力矩阵是下三角矩阵,必然是满秩的,建模能力更强。
-
预训练通用表征能力问题,纯粹的decoder-only架构+next token predicition预训练,每个位置所能接触的信息比其他架构少,要预测下一个token难度更高,当模型足够大,数据足够多的时候,decoder-only模型学习通用表征的上限更高
-
上下文学习为decoder-only架构带来的更好的few-shot性能:prompt和demonstration的信息可以视为对模型参数的隐式微调,decoder-only的架构比encoder-decoder在in-context learning上会更有优势,因为prompt可以更加直接地作用于decoder每一层的参数,微调的信号更强。
-
Causal attention (就是decoder-only的单向attention)具有[隐式的位置编码功能](Haviv, Adi, et al. “Transformer Language Models without Positional Encodings Still Learn Positional Information.”Findings of the Association for Computational Linguistics: EMNLP 2022. 2022.),打破了transformer的位置不变性,而带有双向attention的模型,如果不带位置编码,双向attention的部分token可以对换也不改变表示,对语序的区分能力天生较弱。
-
效率问题,decoder-only支持一直复用KV-Cache,对多轮对话更友好,因为每个token的表示只和它之前的输入有关,而encoder-decoder和PrefixLM就难以做到。
1 Decoder-only架构
纯decoder模型主要是以GPT为代表的生成类模型,引用GPT-1论文的话 “Our model largely follows the original transformer work. We trained a 12-layer decoder-only transformer with masked self-attention heads (768 dimensional states and 12 attention heads). “比transformer多了一倍的层数,此时叠层已经初见端倪。
为什么先讲Decoder-only,因为从外观上看Decoder-only更像是encoder架构,只是将encoder的multi-head-attention换成了mask multi-head-attention。下图是GPT-2论文里提到的Decoder-only模型架构
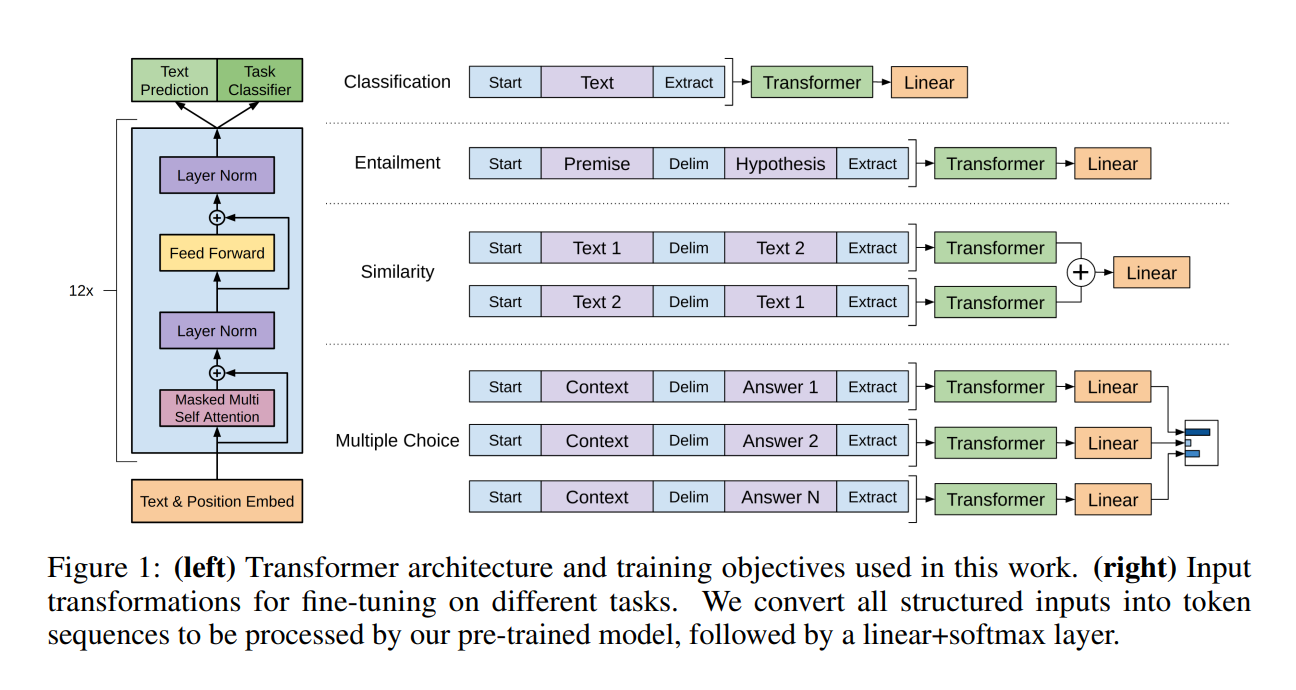
还有知乎博主形象生动地用后面这张图展示了两者的区别:
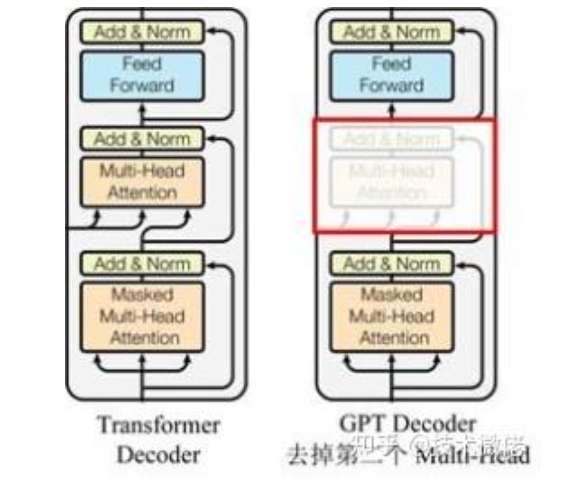
至此,我们了解了两者的架构区别就在于Self-Attention,因此我们接下来可以引入self-attention这个重要模块了。
1.1 自注意力机制(Self-Attention)
todo
1.1.1 理论:Self-Attention注意力机制原理
todo